reading-notes2
https://m7madmomani2.github.io/reading-notes2
About Machine Learning:
-
Machine Learning is defined as the study of computer programs that leverage algorithms and statistical models to learn through inference and patterns without being explicitly programed.
-
Machine learning is not about algorithms. Machine learning is a comprehensive approach to solving problems…
-
Machine learning is the practice of teaching computers how to learn patterns from data, often for making decisions or predictions.
-
For true machine learning, the computer must be able to learn patterns that it’s not explicitly programmed to identify.
-
Model - a set of patterns learned from data.
-
Algorithm - a specific ML process used to train a model.
-
Training data - the dataset from which the algorithm learns the model.
-
Test data - a new dataset for reliably evaluating model performance.
-
Features - Variables (columns) in the dataset used to train the model.

Exploratory Analysis
- This step should not be confused with data visualization or summary statistics. Those are merely tools… means to an end, Proper exploratory analysis is about answering questions. It’s about extracting enough insights from your dataset to course correct before you get lost in the weeds.
- The purpose of exploratory analysis is to “get to know” the dataset. Doing so upfront will make the rest of the project much smoother, in 3 main ways:
1) You’ll gain valuable hints for Data Cleaning (which can make or break your models). 2) You’ll think of ideas for Feature Engineering (which can take your models from good to great). 3) You’ll get a “feel” for the dataset, which will help you communicate results and deliver greater impact. ————————————-
Data Cleaning
-
Data cleaning is the process of fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data within a dataset. When combining multiple data sources, there are many opportunities for data to be duplicated or mislabeled..
-
Data cleanng steps : Remove Unwanted observations from datasets : This includes duplicate or irrelevant observations.
1) Fix Structural Errors : Structural errors are those that arise during measurement, data transfer, or other types of “poor housekeeping.”For instance, you can check for typos or inconsistent capitalization. This is mostly a concern for categorical features, and you can look at your bar plots to check.
2) Filter Unwanted Outliers : Outliers can cause problems with certain types of models. For example, linear regression models are less robust to outliers than decision tree models.In general, if you have a legitimate reason to remove an outlier, it will help your model’s performance.However, outliers are innocent until proven guilty. You should never remove an outlier just because it’s a “big number.” That big number could be very informative for your model.
3) Handle Missing Data : Missing data is a deceptively tricky issue in applied machine learning.First, just to be clear, you cannot simply ignore missing values in your dataset. You must handle them in some way for the very practical reason that most algorithms do not accept missing values.

Feature Engineering
- Feature engineering is about creating new input features from your existing ones, In general, you can think of data cleaning as a process of subtraction and feature engineering as a process of addition.
- This is often one of the most valuable tasks a data scientist can do to improve model performance, for 3 big reasons: 1) You can isolate and highlight key information, which helps your algorithms “focus” on what’s important. 2) You can bring in your own domain expertise. 3) Most importantly, once you understand the “vocabulary” of feature engineering, you can bring in other people’s domain expertise!
Combine Sparse Classes
Sparse classes (in categorical features) are those that have very few total observations. They can be problematic for certain machine learning algorithms, causing models to be overfit.
- There’s no formal rule of how many each class needs.
- It also depends on the size of your dataset and the number of other features you have.
- As a rule of thumb, we recommend combining classes until each one has at least ~50 observations. As with any “rule” of thumb, use this as a guideline.

Algorithm Selection
- we have 5 very effective machine learning algorithms for regression tasks.
- Linear Regression is Flawed
- Regularization in Machine Learning : is a technique used to prevent overfitting by artificially penalizing model coefficients.It can discourage large coefficients (by dampening them).
- Regularized Regression Algos : it has many types such as : Lasso Regression / Ridge Regression / Elastic-Net
- Decision Tree Algos : Decision trees model data as a “tree” of hierarchical branches. They make branches until they reach “leaves” that represent predictions.
-
Tree Ensembles : Ensembles are machine learning methods for combining predictions from multiple separate models. There are a few different methods for ensembling
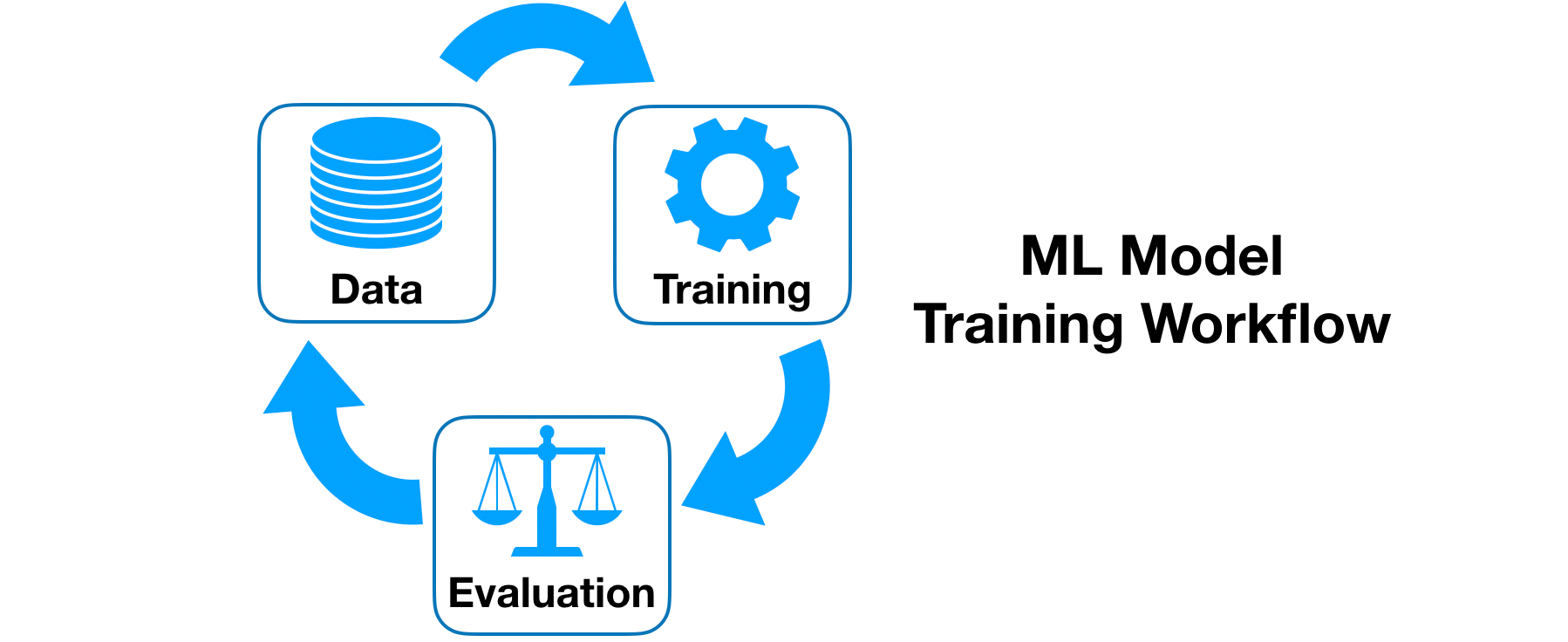
Model Training
-
The process of training an ML model involves providing an ML algorithm (that is, the learning algorithm) with training data to learn from. The term ML model refers to the model artifact that is created by the training process.
- Split Dataset : Let’s start with a crucial but sometimes overlooked step: Spending your data. Think of your data as a limited resource. You can spend some of it to train your model (i.e. feed it to the algorithm). You can spend some of it to evaluate (test) your model. But you can’t reuse the same data for both! If you evaluate your model on the same data you used to train it, your model could be very overfit and you wouldn’t even know! A model should be judged on its ability to predict new, unseen data.
About Hyperparameters
- There are two types of parameters in machine learning algorithms, The key distinction is that model parameters can be learned directly from the training data while hyperparameters cannot. 1) Model parameters : Model parameters are learned attributes that define individual models. 2) Hyperparameters: Hyperparameters express “higher-level” structural settings for algorithms. ———————————————